AIの経済予測は、なぜ揺れるのか ― 30試行で「ブレの正体」を切り分けた
KizashiXでは、決算や経済指標といった実際のイベントを対象に、AI(Claude)に予測を立てさせ、その精度を検証している。その過程で、ひとつの素朴な問題に突き当たった。
同じ決算について、同じAIに、同じように予測させても、出てくる確率が日によって違う。
あるオラクルの決算予測では、ある時は「ビート(上振れ)の確率70%」と出て、別の時には同じ問いで56%と出た。14ポイントの開きである。これは「AIが賢いか/賢くないか」という話に見えるが、検証してみると、まったく違う構造が見えてきた。本稿はその検証の記録である。
まず「測る前」に、解釈を決めた
ブレを目にした時、最初に浮かぶ説明はいくつもある。「AIの気まぐれ」「たまたま」――しかしそうした後付けの解釈は、データを見てから都合よく作られやすい。そこでKizashiXでは、検証を始める前に「どういう結果が出たら、どの仮説を採るか」を先に決めた。
立てた仮説は2つ。
- 根拠の言語化が原因:直前に「予測の根拠を一文で出力させる」変更を入れていた。考えを言葉にさせると、AIが慎重になって確率が動いたのではないか。
- 検索の量が原因:AIは予測のたびにWebを検索して情報を集める。その回数や拾う記事が毎回違うことが、ブレを生んでいるのではないか。
この2つを、別々のテストで切り分けることにした。
仮説1:根拠を書かせたから? ― 棄却
まず、根拠を出力させない設定と、出力させる設定で、それぞれ同じ問いを10回ずつ叩いた。
結果、両群の確率分布はほぼ完全に重なった。根拠なし群の平均と、根拠あり群の平均の差はわずかで、群内のばらつき(標準偏差およそ7ポイント)に埋もれる水準だった。統計的にも有意な差は出なかった。
つまり、最初に見た「70%→56%」は、根拠を書かせたことによる変化ではなく、もともと大きくばらつく分布から、たまたま高い値と低い値を1回ずつ引いただけだった。もっともらしい仮説だったが、データはこれを否定した。
ここで重要なのは、もし測らずにこの仮説を信じていたら、「根拠出力をやめる」という無関係な変更に時間を使っていた、という点である。測ったから、立ち止まれた。
仮説2:検索を増やせば安定する? ― むしろ逆だった
次に、検索の「量」を疑った。情報が足りないから揺れるなら、検索を増やせば安定するはずだ――そう考えるのが自然だろう。
そこで3つの群を比べた。
- 検索フリー:そのまま検索させる(従来どおり)
- 検索5回固定:検索回数を増やして固定する
- ソース固定:検索させず、毎回まったく同じ資料を読ませる
結果は直感に反するものだった。検索を5回に増やしても、ばらつきはほとんど縮まなかった。 それどころか、検索を増やすと「毎回読みにいく記事の一致率」が下がった。回数を増やすほど、AIが拾ってくる記事の顔ぶれが毎回バラけ、読む中身がかえって安定しなくなったのである。
「量を増やす」という直感的な対策は、効かないどころか逆効果だった。これも、立てた仮説が外れたことをデータが示した例である。
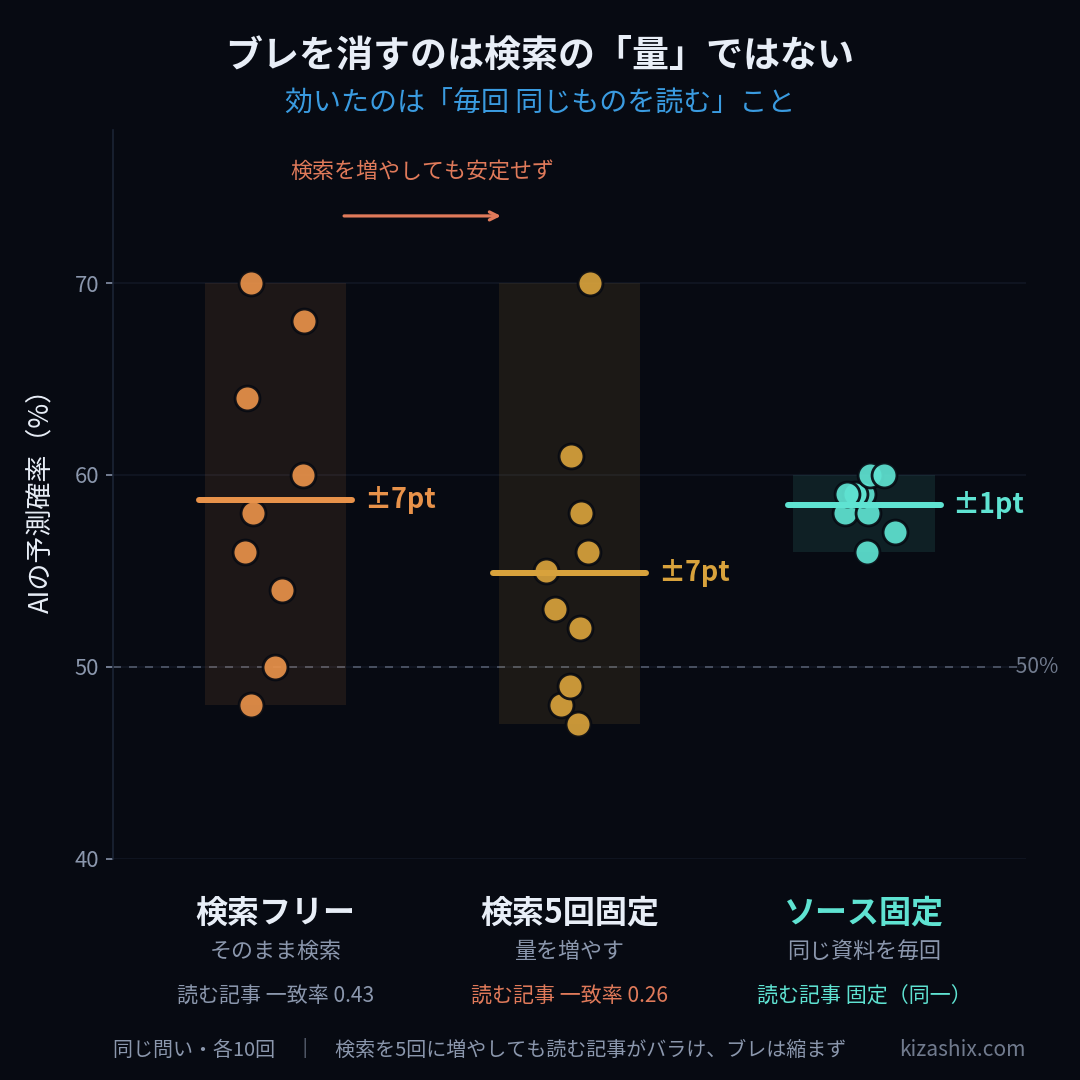
結論:効いたのは「毎回、同じものを読む」こと
決定的だったのは3つ目の群だ。検索をやめ、毎回まったく同じ資料を読ませたところ、ばらつきは劇的に縮んだ。それまで±7ポイントほど揺れていた予測が、±1ポイント級にまで収束した。
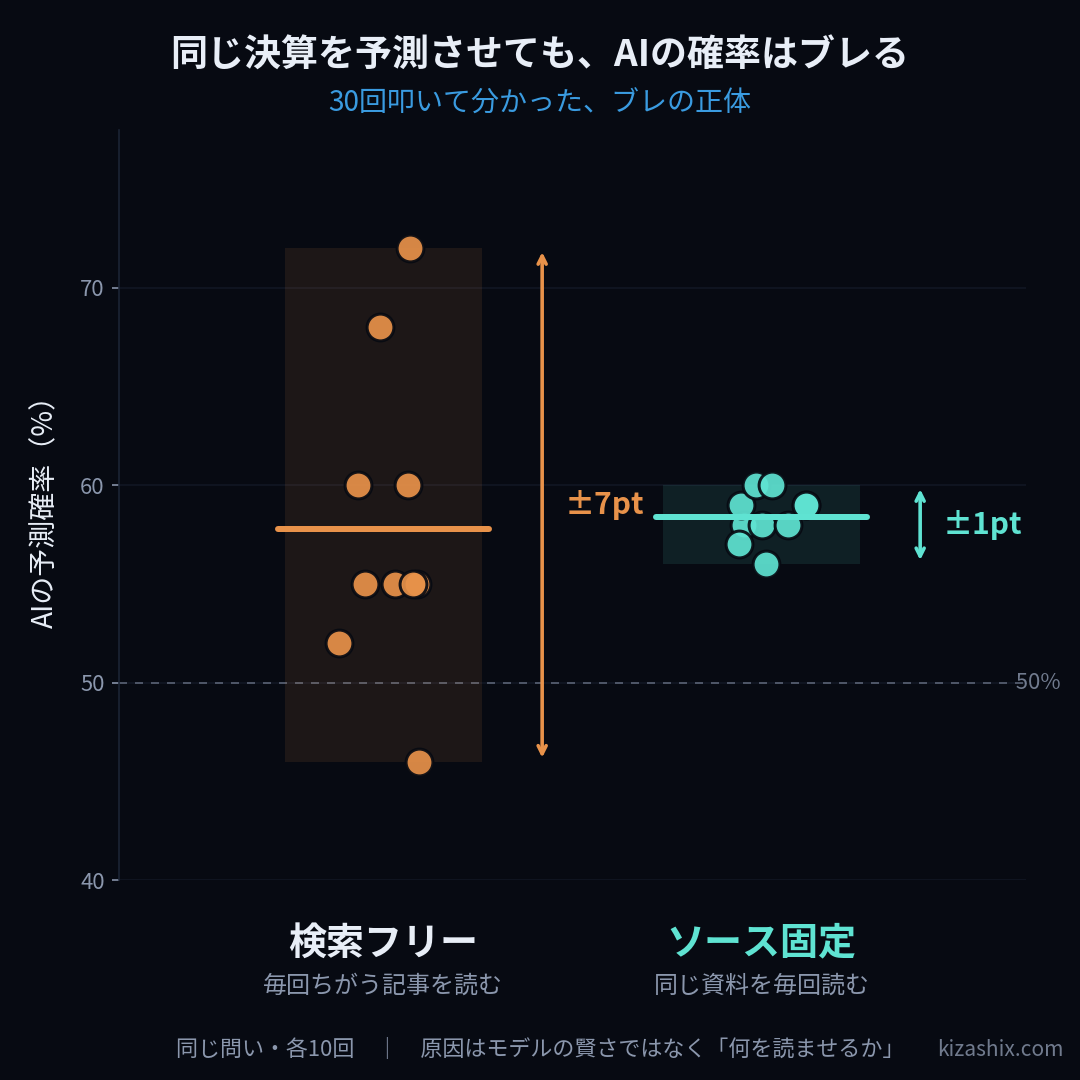
ここから言えることは明快だ。ブレの大半は、AIの推論力の問題ではなく、「毎回違うソースを読んでいたこと」に由来していた。同じ材料を渡せば、AIはほぼ同じ判断を返す。揺れていたのは判断する側ではなく、渡す材料の側だった。料理人が日によって違う料理を出すのではなく、毎日違う食材を渡していた、というのが実態に近い。
完全にソースを固定しても、なお残る±1ポイント程度の揺れがある。これはAIが確率を1点に丸める際の内部的なゆらぎで、複数回の中央値を採ることで実用上は吸収できる水準である。
だから何が言えるか
世の中のAIの議論は「どのモデルが賢いか」に集まりがちだ。しかし今回の検証が示したのは、経済予測においては、モデルの賢さよりも「何を読ませるか」が出力を大きく左右する、ということだった。同じモデルでも、読む資料が安定しなければ予測は揺れ、安定させれば落ち着く。
KizashiXのAI予測では、この知見を踏まえ、各設問について中核となる一次ソースを固定して読ませる方針をとっている。AIに「賢く考えさせる」前に、「同じものを読ませる」こと――地味だが、これが予測を一次データとして扱えるかどうかの分かれ目になる。
最後に一点、付け加えておく。今回の結果は、ひとつの予測設問で確認したものである。「ソースの安定性がブレの主因」という構造が、あらゆる設問・あらゆる形式で同じ比率で成り立つかは、別途の検証を要する。検証は続く。
本稿はAIによる予測の挙動に関する技術的な検証記録であり、特定の銘柄・投資行動を推奨するものではありません。